Native feeds
OpenCTI provides versatile mechanisms for sharing data through its built-in feeds, including Live streams, TAXII collections, and CSV feeds.
Feed configuration
Feeds are configured in the "Data > Data sharing" window. Configuration for all feed types is uniform and relies on the following parameters:
- Filter setup: The feed can have specific filters to publish only a subset of the platform overall knowledge. Any data that meets the criteria established by the user's feed filters will be shared (e.g. specific types of entities, labels, marking definitions, etc.).
- Access control: A feed can be either public, i.e. accessible without authentication, or restricted. By default, it's accessible to any user with the "Access data sharing" capability, but it's possible to increase restrictions by limiting access to a specific user, group, or organization.
By carefully configuring filters and access controls, you can tailor the behavior of Live streams, TAXII collections, and CSV feeds to align with your specific data-sharing needs.
Live streams
Introduction
Live streams, an exclusive OpenCTI feature, increase the capacity for real-time data sharing by serving STIX 2.1 bundles as TAXII collections with advanced capabilities. What distinguishes them is their dynamic nature, which includes the creation, updating, and deletion of data. Unlike TAXII, Live streams comprehensively resolve relationships and dependencies, ensuring a more nuanced and interconnected exchange of information. This is particularly beneficial in scenarios where sharing involves entities with complex relationships, providing a richer context for the shared data.
In scenarios involving data sharing between two OpenCTI platforms, Live streams emerge as the preferred mechanism. These streams operate like TAXII collections but are notably enhanced, supporting:
- create, update and delete events depending on the parameters,
- caching already created entities in the last 5 minutes,
- resolving relationships and dependencies even out of the filters,
- can be public (without authentication).
Resolve relationships and dependencies
Dependencies and relationships of entities shared via Live streams, as determined by specified filters, are automatically shared even beyond the confines of these filters. This means that interconnected data, which may not directly meet the filter criteria, is still included in the Live stream. However, OpenCTI data segregation mechanisms are still applied. They allow restricting access to shared data based on factors such as markings or organization. It's imperative to carefully configure and manage these access controls to ensure that no confidential data is shared.
Illustrative scenario
To better understand how live streams are working, let's take a few examples, from simple to complex.
Given a live stream with filters Entity type: Indicator AND Label: detection. Let's see what happens with an indicator with:
- Marking definition:
TLP:GREEN - Author
Crowdstrike - Relation
indicatesto the malwareEmotet
| Action | Result in stream (with Avoid dependencies resolution=true) |
Result in stream (with Avoid dependencies resolution=false) |
|---|---|---|
| 1. Create an indicator | Nothing | Nothing |
2. Add the label detection |
Create TLP:GREEN, create CrowdStrike, create the indicator |
Create TLP:GREEN, create CrowdStrike, create the malware Emotet, create the indicator, create the relationship indicates |
3. Remove the label detection |
Delete the indicator | Delete the indicator and the relationship |
4. Add the label detection |
Create the indicator | Create the indicator, create the relationship indicates |
| 5. Delete the indicator | Delete the indicator | Delete the indicator and the relationship |
Details on how to consume these Live streams can be found on the dedicated page.
TAXII Collections
OpenCTI has an embedded TAXII API endpoint which provides valid STIX 2.1 bundles. If you wish to know more about the TAXII standard, please read the official introduction.
In OpenCTI you can create as many TAXII 2.1 collections as needed.
After creating a new collection, every system with a proper access token can consume the collection using different kinds of authentication (basic, bearer, etc.).
As when using the GraphQL API, TAXII 2.1 collections have a classic pagination system that should be handled by the consumer. Also, it's important to understand that element dependencies (nested IDs) inside the collection are not always contained/resolved in the bundle, so consistency needs to be handled at the client level.
CSV feeds
Introduction
The CSV feed facilitates the automatic generation of a CSV file, accessible via a URL. The CSV file is regenerated and updated at user-defined intervals, providing flexibility. The entries in the file correspond to the information that matches the filters applied and that were created or modified in the platform during the time interval (between the last generation of the CSV and the new one).
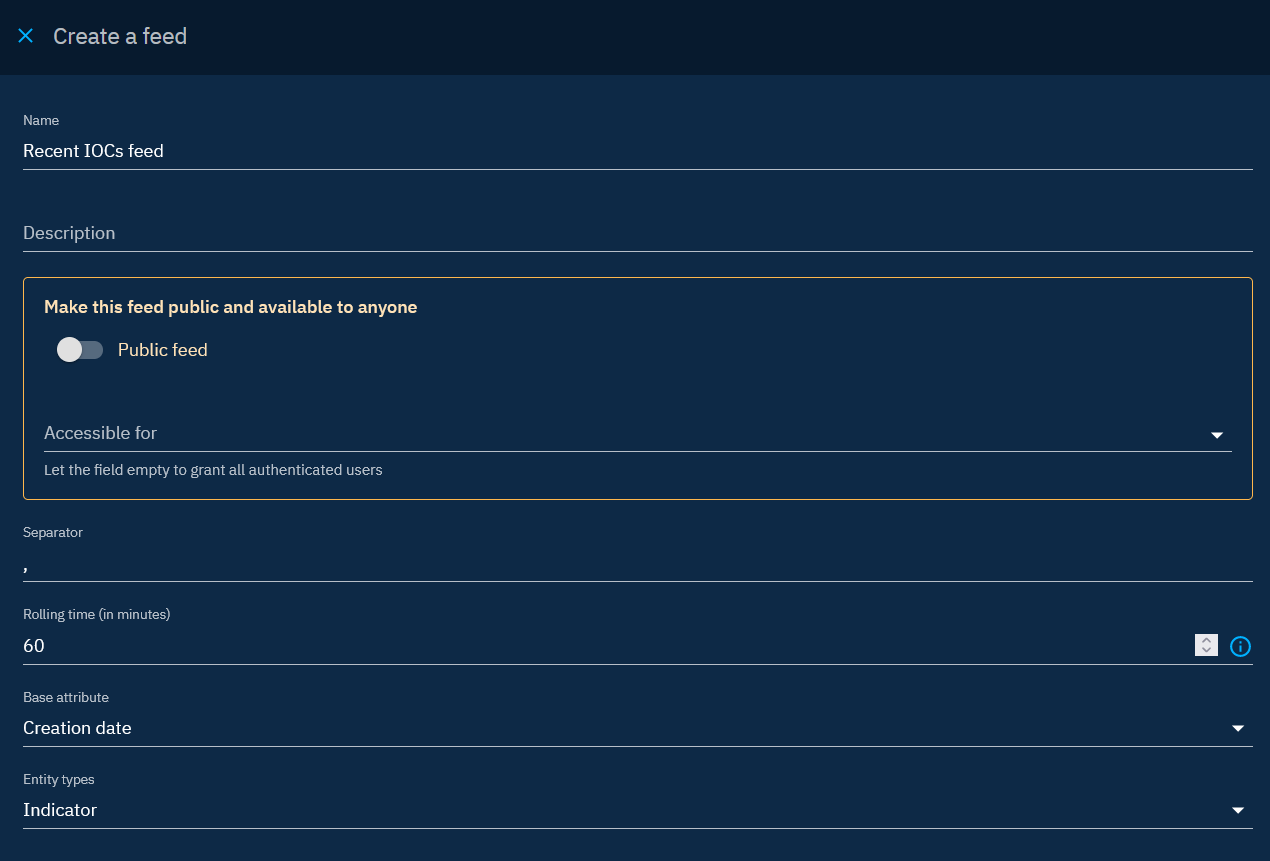
Rolling Time & Base Attribute
The Rolling Time value (represented in minutes) determines how far back in time OpenCTI should look for data that matches your filters since the last fetch. The Base Attribute value determines whether OpenCTI should look for data created within the Rolling Time period, or data updated within the Rolling Time period.
Relationship-based columns (neighbor resolution)
By default, CSV feed columns map directly to attributes of the selected entity type (e.g., an Indicator's value, confidence, or pattern_type). With relationship-based columns, you can also include attributes from first-degree neighbors resolved through relationships at runtime.
For example, an Indicator-based feed can include columns like Malware Name, Campaign Name, or Intrusion Set Name — pulled from entities connected to the Indicator via indicates relationships — without any additional API calls from the consumer.
Configuring a relationship column
In the column configuration section, each entity type mapping can be toggled between two modes:
- Direct (default) — maps to a direct attribute of the entity itself.
- Relationship — resolves a neighbor through a relationship and extracts an attribute from the resolved entity.
Click the Direct / Relationship chip next to the entity type name to toggle between modes.
When in Relationship mode, three fields appear in a row:
- Relationship type — the relationship to follow (e.g.,
indicates,uses,attributed-to). Only relationship types valid for the selected entity type are shown, in both directions. - Target type — the type of neighbor entity to resolve (e.g.,
Malware,Intrusion-Set). Scoped based on the selected relationship type. - Attribute — the attribute to extract from the resolved neighbor (e.g.,
name,description,aliases).
Multi-match behavior
When multiple neighbors match (e.g., an Indicator indicates two different Malware), the behavior is configurable per column:
- Strategy: All (list) joins all matched values, First match takes only the first.
- List separator: configurable separator for joining multiple values (defaults to
,). Must differ from the feed's CSV separator to avoid parsing ambiguity.
These options appear automatically in the column header row when any mapping in that column uses Relationship mode.
Example
| Indicator Value | Malware Name | Campaign Name | Indicator Type | Confidence |
|---|---|---|---|---|
| 1.2.3.4 | EvilLoader, DarkAgent | Operation X | IPv4-Addr | 85 |
Here, Malware Name and Campaign Name are resolved at runtime through relationships, while Indicator Value, Indicator Type, and Confidence are direct attributes.
Duplication
To easily configure a new CSV feed, you can choose to start from an existing feed configuration and duplicate it. The "duplicate" action is accessible from the feed burger menu.
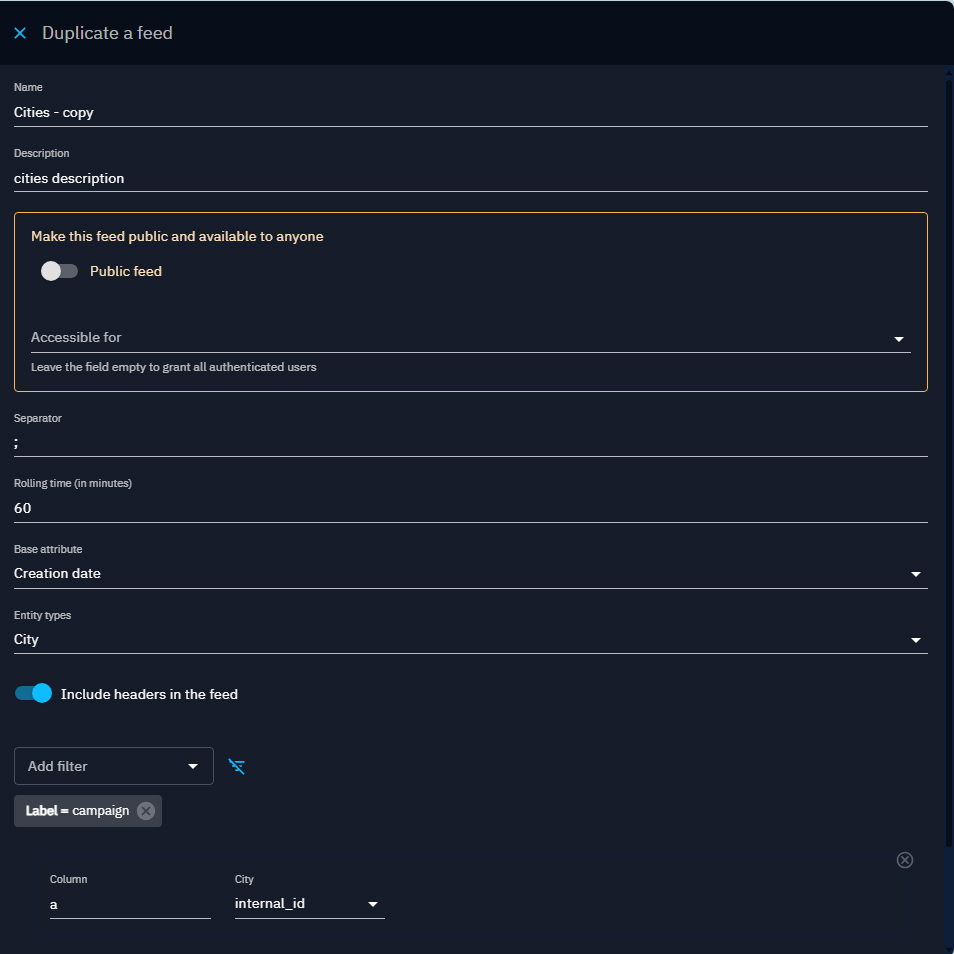
When you duplicate the CSV feed, all fields are copied to the creation form and can be edited. The new feed is named with a "-copy" suffix.
CSV size limit
The CSV data generated from a CSV feed has a limit of 5 000 entries by default. If more than 5 000 entities are retrieved by the platform, only the most recent 5 000 will be shared in the file.
You can change this limit by setting the corresponding environment variable:
Or in the platform configuration file:
Performance considerations
Changing the size limit can lead to performance degradation depending on your platform and your CSV feed configuration. Please test your setup properly and align this number with your platform capacity to avoid any problem.
Sharing a Public CSV Feed, Taxii collection or stream
To share any data using one of the above methods in a public way, two conditions must be met:
- The user must have the capability Manage Data sharing (see capabilities)
- The user must have the capability Manage credentials (see capabilities)
When these two conditions are met, the user can enable the feed to be public.
In this case, the user must choose a user whose rights will be used to share the data, including markings, organisation membership (for organisation segregation), and authorized members.
This helps ensure that data sharing is controlled and that data is not leaked.
Example
I want to share a TAXII collection publicly. I have the required capabilities to do so. I chose a user, UserA, who has access to markings up to TLP:GREEN and is part of the Organisation Filigran.
- If a report is created with TLP:RED, it won't be included in the TAXII collection because my user does not have access to it.
- In the context of organisation segregation, if a report is created and shared to organisation "OrganisationB", and my user is part of "Filigran" (which is not the platform organisation), this report won't be included.
Feeds having "system" as user used for impersonation
It may happen that some platform have "system" as a user used for impersonation: this is a case for historic feeds. In this case, the system user is used for impersonation, meaning that any data present in the platform will be shared.
User used for impersonation is deleted
If a user that was used for the access right impersonation is deleted from the platform, any public feed using this user will be stopped.
Additionnally, these feeds will be made private.